 德阳吧
德阳吧AMD 锐龙 AI 9 365 处理器性能测试
博主 Da vid Huang 对搭载 Strix Point 锐龙 AI 9 365 处理器的笔记本电脑工程机进行了测试,简要分析移动 Zen 5 核心的性能,详细请看下文介绍
这周从某不知名小厂工作的朋友那里借到了 Strix Point 工程机,有机会在笔记本正式发售前体验一段时间。于是我运行了一系列的测试,从微架构与性能两方面提前体验时隔两年的 AMD 新微架构。
由于只有几个小时的时间,这次就只针对 CPU 部分简单跑了一些现成的跑分而没有仔细深究微架构的每一个细节。如果有必要,后续 Zen5 量产版本发售之后我会再做一些补充。
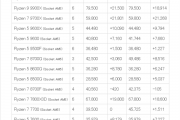
处理器参数
Strix Point 系列首发的两个 SKU 分别是HX 370和365,均仅支持 FP8 封装。首发时仅支持 LPDDR5x 内存,本次测试的平台为 LPDDR5x-7500 32GB。在移动端处理器连续4代提供8核移动端处理器、连续3代使用原生8核心的CCX之后,Strix Point 终于大幅度修改了核心配置。Strix Point 是一个原生12核心的处理器,并且由非对称的两个 CCX 组成:
- CCX0: 4个核心,搭配 16 MB L3 缓存
- Zen 5 青春版大核心:相比桌面/服务器的完整版 Zen 5,其最高频率从 5.7 GHz 降低到 5.1 GHz,SIMD 吞吐减半,对应的 L1 向量load带宽也减半
- CCX1: 6或8个核心,搭配 8 MB L3 缓存
- Zen 5c 小核心:使用与大核完全相同的微架构,在后端物理设计层面继续降低Fmax target以缩减面积,频率不超过4 GHz。
AMD 官网没有写明小核参数,经过实测可得365小核频率为 3.3 GHz,HX 370则只有后续再进行测试才知道。与 Phoenix2 不同的是,Strix Point处理器大小核可同时跑满各自的最大频率,而不会出现互相拖累的问题。
微架构特性
与 Zen 4 相对微小的改动不同的是,Zen 5是一个“ground-up”的全新微架构,其地位与 Zen 3 相近。因此它也开启了新的篇章:CPUID family从19h (25) 改为 1Ah (26)。本文选取了一些比较基础的微架构测试数据整理发布。指令吞吐
使用 InstructionRate 工具分别测量 Zen 3/4/5 的指令吞吐/延迟,

从上面的测试中可以看出,Zen 5 相比 Zen 4 的改动有进有退:
- 大幅度增加各种 scalar ALU 指令的吞吐,但由于移动端Zen 5的向量单元相比桌面与服务器减半,在本次测试中相比Zen 4的SIMD吞吐基本维持不变。即便是在向量单元减半的Zen 5核心上,所有宽度的SIMD store操作依然相比前代翻倍,SIMD load store 吞吐达到 1:1;
- 大幅度增强分支处理能力,每周期可处理的 non-taken branch 从两个增加到3个,且每周期可处理两个 taken branch。这个应该与新的前端设计有关;
- 128/256/512bit 的 SSE/A VX/A VX512 SIMD 整数加法计算的延迟全部增加到2周期,这个改动可能是为了让维持高频变得更容易;
- 128/256bit SIMD 整数加法运算吞吐相比Zen 4全部减半,但512bit不变。推测这个问题只在 SIMD减半的Zen 5核心上存在,可能与 port 分配有关;
- 移除 Zen 4 引入的 nop fusion 功能。现在不再可以将 nop 指令与另一条指令合并在同一个 macro-op 上;
- 调整了一些逻辑寄存器操作的吞吐,将一部分 mov 以及一部分寄存器 zeroing 吞吐统一为5,相比 Zen 4 有增有减;
取指令、解码与macro-op cache
Zen 5目前公开的信息里没有太详细地提到前端的规模,只有一个提到前端指令吞吐最多翻倍的页面。

除此之外AMD还提到一个关键词:“Parallel dual pipe front-end”,这个设计让人联想到两年前公布的两个专利:
通过运行不同指令长度、不同指令数量的NOP指令,我们可以较为容易地观测取指令、解码与 macro-op cache 的行为。从这个测试中,我们可以看出 Zen 5 的前端相比 Zen 4 有着相当特殊的表现。首先从2字节的NOP开始:

在这个测试里,可以看到Zen 5单线程运行2字节NOP的取指令能力并没有相对Zen 4表现出任何明显优势(除去 macro-op cache 内的吞吐略微提升了一些),且在以下情况下相对劣势:
- 可观测到的 macro-op cache 减少。Zen 4在8-12KB(也就是对应4k-6k条指令)的吞吐下降幅度相比Zen 5更为平缓,推测Zen 5将 macro-op cache 减少到与Zen 3相同的4k条;
- 出缓存后从DRAM取指令的带宽减半,推测单线程最大in-flight L1i$ miss减半。
继续使用4字节NOP指令观察,可以看出Zen 4在这个测试里触发了NOP融合,因此 macro-op cache的NOP吞吐和等效容量翻倍,而Zen 5则维持了相似的表现——macro-op cache内IPC略大于6,单线程等效为4宽的x86解码。而4字节指令不仅会出现DRAM fetch带宽下降,从L3 fetch也观察到带宽减半。开启SMT后则可在L2内做到8宽解码,L3 fetch 带宽也恢复正常。

在8字节NOP的测试中,由于4096条指令的 macro-op cache 可以完全覆盖32K L1i,因此无法准确判断这种情况下的x86解码性能,只能看出Zen 4/Zen 5各自走 macro-op cache 时的指令吞吐分别为6和8。

从上述测试中可以猜个八九不离十:
- Zen 5采用了与Tremont相似但更宽的多前端设计,采用两个4宽的x86解码器,搭配至少8宽的 macro-op cache 实现8宽 rename;
- 考虑以下现象
- Zen 5单线程运行连续的NOP指令时并不能让x86解码带宽超过4;
- 在指令吞吐小节中测试得出其单周期可以处理两个taken branch;
- 合理推测Zen 5没有采用类似Gracemont的predecode ILD缓存方案,而是必须在分支预测器预测发生taken branch时才能让两个解码同时工作,也就是直接让其中一个解码器去从下一个分支目标地址开始解码。从这个角度来看,AMD本代依然需要依赖 macro-op cache 来实现分支较为稀疏的场景的高吞吐;
- Zen 5不仅要支持同一周期从两个位置开始解码 x86 指令,也要支持同一周期从 macro-op cache 中的两个位置分别 fetch 指令,以实现 macro-op cache 覆盖范围内的每个周期处理两个 taken branch;
- 当核心运行两个SMT线程时,可以各自独占一个解码器使整个核心的x86解码吞吐上限在大部分情况下达到8。
个人推测在不久的将来,macro-op cache可能会被从 Zen 核心上完全移除,从而转向更为灵活的predecode ILD缓存方案来解决x86可变长度宽解码问题。同时,AMD可以增加多组解码器的数量以轻松为高性能核心实现更宽的x86解码(同时支持单周期处理更多的 taken branch),或减少解码器数量为低功耗核心实现更节能、面积更小的x86解码。
访存延迟与带宽
Zen 5并没有对缓存容量和核心拓扑进行非常大的改动,因此跑一些比较常规的测试。

从上图可以看出,
- Zen 5将L1缓存增加到48 KB并且延迟维持4周期不变。
L1延迟性能优于Ice Lake之后实现48KB L1的微架构,与即将发布的 Arrow Lake (Lion Cove) 相同。 - L2延迟属性整体维持不变(1MB 14周期)
- L3延迟从50周期降低到46周期左右。
考虑到Zen 5的频率并没有非常大的下降,可以认为它的L3延迟获得了小幅度进步。

可以看出,
- SIMD规格减半的Zen 5的L1读取带宽与Zen 4基本相同,均为每周期64字节;
- 与L1不同的是,L2带宽翻倍的属性被保留;
- 单线程读取L3的带宽更接近理论的每周期32字节,而Zen 4只有每周期24字节左右。
Strix Point 处理器再次引入双CCX设计引发了一些人对跨CCX同步性能的担忧,因此本文也进行了简单的跨核心同步的性能测试。


可以看出,Strix Point的两组核心在不同的CCX内,表现与一般的 Ryzen 没有什么明显区别。跨 CCX 同步的延迟偏高(大约是桌面 Ryzen 的两倍左右),可能与 FCLK 频率动态调节等因素有关。
性能实测
由于时间关系,本次选取了SPEC CPU 2017 rate-1、Geekbench 5/6的单核/多核,分别对高频的Zen 5以及低频的Zen 5c进行测试。- 其中Geekbench测试时间较短,因此所有设备运行于默认最高频率(frequency governor配置到“performance”);
- SPEC CPU 2017运行时间较长,其中500和548等子项的局部发热非常严重,单核运行测试也会撞温度墙。在对Ryzen AI 9 365进行测试时,部分情况下频率会降低到4.9 GHz左右。为获得准确数据,在SPEC测试中将所有处理器使用CPPC限制到4.8 GHz同频对比。
- “Relative Performance”以7735U为基准,计算所有其它处理器的提升幅度
- “IPC uplift”则以前代为基准计算IPC提升幅度。Zen 4的IPC提升幅度相对Zen 3计算,Zen 5/5c相对Zen 4计算。

观察子项成绩可以发现,500.perlbench_r的提升较大,达到了24%。而525.x264_r几乎没有性能提升,531.deepsjeng_r甚至发生性能下降(-5%)。以这三个测试为例进行一些简短的分析(猜测为主):
- perlbench是AMD的传统劣势,其性能瓶颈被L1容量、load/store能力的提升很好地缓解。除此之外perlbench的ILP较好,分支指令数量适中,可能可以较好地发挥新的前端吞吐提升;
- x264主要是执行单元瓶颈,编译器自动向量化生成了大量SIMD整数运算代码。通过前面的分析可以发现,Strix Point上的Zen 5不仅在这方面毫无进步,甚至还有相当大的退步。那么微架构方面的提升极有可能被这些SIMD方面的削减抵消,想要在这个测试里获得完整的Zen 5性能可能只能等待桌面版;
- 在之前针对Zen 4运行SPEC的性能计数器分析中可以看出,531子项哪怕是在拥有 6.75K macro-op cache 的Zen 4核心上运行也会造成相当高的 macro-op cache MPKI。而Zen 5这方面有较为明显的削减会进一步拉低命中率,推测IPC下降与此有一定的关联。
Geekbench
从整体看,Zen 5在 Geekbench 5/6 中的IPC提升比较符合官方宣传(在没有 FP/ML 子项刷分的情况下做到了大约15%-17%的提升),好于 SPEC CPU 2017 int rate 的提升。
需要注意的是,Geekbench 6 的 Object Detection 子项会使用 A VX512-VNNI 或者 A VX-VNNI 进行加速,因此 Zen 4相比 Zen 3 在此项测试中性能超过翻倍,拉高了平均数。而移动端 Zen 5 相比 Zen 4 并没有提高 A VX512 吞吐,在此项测试中的提升并不占优。由于 Geekbench 6 的这些改动,我认为 Geekbench 5 的整数子项放在今天依然比 Geekbench 6 更加具备参考价值。




总结
Zen 5 是世界上首个 8-wide rename 的 x86 微架构。本次 AMD 一反常态地将 Zen 5 移动端 APU 首先展示出来,但不幸的是无论是大核还是小核都并非性能最好的完全体。移动端一如既往减半的缓存、以往没有出现过的减半 SIMD 单元、较上代更低的频率,无不意味着 Zen 5 移动平台和桌面版本的综合性能差距将会来到史无前例的级别。好在通过测试 Strix Point 已经可以足够了解这个微架构的设计思想和最重要的新特性,以解答那个老生常谈的问题——x86 作为一个复杂的变长指令,在这个RISC当道的时代,未来应该何去何从?在我看来,当 Intel 目前最有活力的 atom 团队与后来者 AMD 给出了相同的结论时,我相信答案已经离我们不远了。期待后续有机会进行更多的详细完整测试。
声明:本文仅为博主 Da vid Huang个人测试,测试使用的一切设备、工具等资产与本人所在公司/职位无关,也没有接受任何赞助。由于使用非正式版系统固件/软件,测试结论可能与零售设备有少许差异,仅供参考.
版权声明
本站所有文章来源于本站原创或网络,如有侵权请联系删除。文章观点并不代表本站观点,请网友自行判断,如涉及投资、理财请谨慎应对!





作者文章
- 八部门发文:加快推出新一代人工智能手机、智能电脑等 23小时前
- 靠美国翻盘 日本钢铁公司要夺回世界第一:快到中国钢铁巨头一半水平了 23小时前
- 全球智能手机大盘连跌9周!华为逆势增长 领跑全行业 23小时前
- 苹果又一次妥协!巴西iOS正式开放第三方商店、外部支付 23小时前
- 韩国半导体业员工赚麻了 买房买车一个不落 23小时前
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。